動機はさておき、こちらのエントリ を読んで気になっていた Keras を触ってみたのでメモ。自分は機械学習にも Python にも触れたことはないので、とりあえず、サンプルコードを読み解きながら、誰しもが通るであろう(?)MNIST データセットの識字をやってみた。表題の通り、用いたモデルは MLP(Multi-Layer Perceptron)。また、今回描いたコードには丁寧にコメントをつけたつもりなので、同じことをやろうとしている方の手助けになれば幸いです🙏
Keras
Keras は最小限で記述できる,モジュール構造に対応しているニューラルネットワークのライブラリです。Pythonによって記述されており、TensorflowやTheanoに対応しています。 革新的な研究、開発を行うためにはアイデアから結果まで最小限の時間で行うことが求められます。そこでKerasはより早い実装、改良を行うことを目的として開発されました。
日本語のドキュメントもあって、コンセプトも共感できる。Google 先生の TensorFlow(こちらも触ってみたかった)をバックエンドというカタチでラッピングしているらしい。なお、Keras 自体の作者も Google の方の模様。
準備
$ python --version
Python 3.5.1
インストールは以下で終わり。簡単。
$ pip install keras
$ pip list | grep Keras
Keras (1.0.5)
サンプルコードを愚直に実行
GitHub にある サンプルコード を落としてきて実行してみると、以下のような感じになる。学習している雰囲気が出ていて、眺めているだけで楽しい。
$ python mnist_mlp.py
Using Theano backend.
60000 train samples
10000 test samples
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
dense_1 (Dense) (None, 512) 401920 dense_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 512) 0 activation_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 512) 262656 dropout_1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 512) 0 dense_2[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 512) 0 activation_2[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 10) 5130 dropout_2[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 10) 0 dense_3[0][0]
====================================================================================================
Total params: 669706
____________________________________________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
9600/60000 [===>..........................] - ETA: 9s - loss: 0.5566 - acc: 0.8247
で、最終的には以下のような結果となった。テストデータに対して 98.16% で識字できているらしい。すごい。
Epoch 19/20
60000/60000 [==============================] - 13s - loss: 0.0192 - acc: 0.9955 - val_loss: 0.1210 - val_acc: 0.9820
Epoch 20/20
60000/60000 [==============================] - 13s - loss: 0.0189 - acc: 0.9953 - val_loss: 0.1194 - val_acc: 0.9816
Test score: 0.11935520198
Test accuracy: 0.9816
バックエンドを TensorFlow に切り替える
デフォルトのバックエンドは Theano なので、これを TensorFlow に切り替えてみる。といっても、やることは ~/.keras/keras.json(上記のサンプルコードを実行した際にできているはず)の中の backend を theano から tensorflow に書き換えるだけ。
TensorFlow 自体のインストール方法は こちら。pip を使えば簡単にできる。ちなみに、自分のバージョンは以下。
$ pip list | grep tensorflow
tensorflow (0.9.0)
サンプルコードを読み解きつつ、整理してみる
とりあえず、初っ端からわからない。まずは以下の部分。
# the data, shuffled and split between train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
なにやらデータセットを準備している模様。考えてもよくわかんないので中身を出力してみることにした。Python も初めてだけど、ググりつつがんばる。とりあえず、X_train と y_train に絞って中身を見てみる。
# -*- coding: utf-8 -*-
import sys
import numpy as np
np.random.seed(20160715)
from keras.datasets import mnist
from keras.utils import np_utils
(X_train, y_train), (X_test, y_test) = mnist.load_data()
for xs in X_train[0]:
for x in xs:
sys.stdout.write('%03d ' % x)
sys.stdout.write('\n')
print('first sample is %d' % y_train[0])
Y_train = np_utils.to_categorical(y_train, 10)
sys.stdout.write('[')
for y in Y_train[0]:
sys.stdout.write('%f ' % y)
sys.stdout.write(']\n'))
上記コードを実行すると、出力は以下のようになる。
Using TensorFlow backend.
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 003 018 018 018 126 136 175 026 166 255 247 127 000 000 000 000
000 000 000 000 000 000 000 000 030 036 094 154 170 253 253 253 253 253 225 172 253 242 195 064 000 000 000 000
000 000 000 000 000 000 000 049 238 253 253 253 253 253 253 253 253 251 093 082 082 056 039 000 000 000 000 000
000 000 000 000 000 000 000 018 219 253 253 253 253 253 198 182 247 241 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 080 156 107 253 253 205 011 000 043 154 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 014 001 154 253 090 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 139 253 190 002 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 011 190 253 070 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 035 241 225 160 108 001 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 081 240 253 253 119 025 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 045 186 253 253 150 027 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 016 093 252 253 187 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 249 253 249 064 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 046 130 183 253 253 207 002 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 039 148 229 253 253 253 250 182 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 024 114 221 253 253 253 253 201 078 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 023 066 213 253 253 253 253 198 081 002 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 018 171 219 253 253 253 253 195 080 009 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 055 172 226 253 253 253 253 244 133 011 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 136 253 253 253 212 135 132 016 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000
first sample is 5
[0.000000 0.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.000000 ]
5 っぽい!!!5 っぽいよ!!!!!
ということで、これ以外にもいろいろ中身を出力してみてわかったことを整理すると、どうやら以下のような感じらしい。
X_train:訓練データ(入力)X_test:テストデータ(入力)Y_train:訓練データ(出力)Y_test:テストデータ(出力)
# MNIST データセットを取り込む
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 変換前:28 x 28 の2次元配列 x 60,000
# 変換後:784要素の1次元配列 x 60,000(256階調を 0 〜 1 に正規化)
X_train = X_train.reshape(60000, 784).astype('float32') / 255
X_test = X_test.reshape(10000, 784).astype('float32') / 255
# 変換前:0 〜 9 の数字 x 60,000
# 変換後:10要素の1次元配列(one-hot 表現) x 60,000
# - 0 : [1,0,0,0,0,0,0,0,0,0]
# - 1 : [0,1,0,0,0,0,0,0,0,0]
# ...
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
ふむ。なんとなくわかってきた気がする。
という感じで、Keras のドキュメントと照らし合わせつつコードを整理しながら、全部コメントをつけてみたのが以下。
# -*- coding: utf-8 -*-
import numpy as np
np.random.seed(20160715) # シード値を固定
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utils
# MNIST データセットを取り込む
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 変換前:28 x 28 の2次元配列 x 60,000
# 変換後:784要素の1次元配列 x 60,000(256階調を 0 〜 1 に正規化)
X_train = X_train.reshape(60000, 784).astype('float32') / 255
X_test = X_test.reshape(10000, 784).astype('float32') / 255
# 変換前:0 〜 9 の数字 x 60,000
# 変換後:10要素の1次元配列(one-hot 表現) x 60,000
# - 0 : [1,0,0,0,0,0,0,0,0,0]
# - 1 : [0,1,0,0,0,0,0,0,0,0]
# ...
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
# シーケンシャルモデル
model = Sequential()
# 隠れ層 1
# - ノード数:512
# - 入力:784次元
# - 活性化関数:relu
# - ドロップアウト比率:0.2
model.add(Dense(512, input_dim=784))
model.add(Activation('relu'))
model.add(Dropout(0.2))
# 隠れ層 2
# - ノード数:512
# - 活性化関数:relu
# - ドロップアウト比率:0.2
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
# 出力層
# - ノード数:10
# - 活性化関数:softmax
model.add(Dense(10))
model.add(Activation('softmax'))
# モデルの要約を出力
model.summary()
# 学習過程の設定
# - 目的関数:categorical_crossentropy
# - 最適化アルゴリズム:rmsprop
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 学習
# - バッチサイズ:128
# - 学習の繰り返し回数:20
model.fit(X_train, Y_train,
batch_size=128,
nb_epoch=20,
verbose=1,
validation_data=(X_test, Y_test))
# 評価
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss :', score[0])
print('Test accuracy :', score[1])
活性化関数・目的関数・最適化アルゴリズムについては、こちらのオンライン書籍 を読んでいたので、ざっくりと何者なのかはわかっていたけど、それぞれどういう感じで選択すればいいのかはまださっぱりわかってない。ドロップアウト比率についても、過学習を抑制するために設定するものらしい、くらいの理解。という感じで、細かいところの理解は追いついていないけれど、難しそうな数式達を直感で理解できるレベルまでモデリングしてくれている Keras はすごいと思う。ここまでできれば、少しずつ設定を変えてトライアンドエラーである程度進んでいける気がする。
ということで、最終的なコードは GitHub にアップしました。
https://github.com/m0t0k1ch1/keras-sample/blob/master/mnist_mlp.py
冒頭でも紹介した こちらのエントリ を参考に、学習過程をグラフで出力するためのコードを付け加えています。
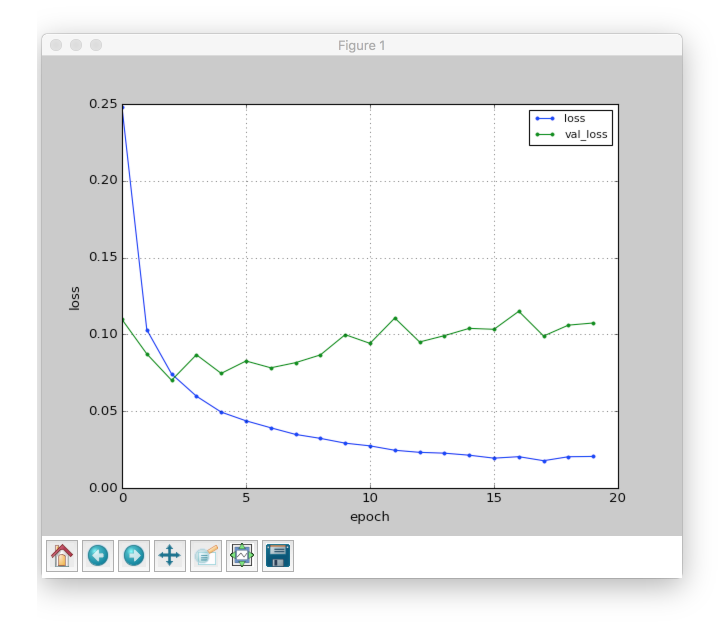
実行すると、以下のようなグラフが得られます。きちんと loss が減少してる。
次
DeepMind の思想に近づいていきたいので、DQNをKerasとTensorFlowとOpenAI Gymで実装する っぽいことをやってみたい。